Hoofdstuk 6 Ontwerp
6.1 Inleiding
Veel van de problemen met validiteit, die we bespraken in Hoofdstuk 5, kunnen voorkomen worden door goede gegevens op een goede manier te verzamelen. Het ontwerp (Eng. “design”) van een onderzoek geeft aan volgens welk schema of plan de gegevens verzameld zullen worden. Als we een goed en sterk ontwerp gebruiken, dan kunnen we daarmee al veel mogelijke bedreigingen voor de validiteit neutraliseren. Dat maakt ons onderzoek sterker. Het is dus raadzaam om een onderzoeksontwerp vooraf heel goed te doordenken! Uiteraard moet het ontwerp nauw aansluiten bij de vraagstelling: de gegevens uit het onderzoek moeten de onderzoeker immers in staat stellen om een valide antwoord te geven op de onderzoeksvraag.
De onderzoeksontwerpen die we in dit hoofdstuk bespreken vormen slechts een beperkte selectie uit de mogelijke ontwerpen. Sommige ontwerpen bespreken we vooral om aan te geven wat er mis kan gaan bij een “zwak” ontwerp; andere ontwerpen zijn juist populair omdat ze relatief “sterk” onderzoek mogelijk maken.
Een onderzoeksontwerp is opgebouwd uit verschillende elementen:
- tijd, meestal afgebeeld als verstrijkend in de leesrichting. De tijdsvolgorde is van belang om een causaal verband vast te stellen: eerst de oorzaak, daarna het gevolg (§5.2). De tijdsvolgorde is echter een noodzakelijke voorwaarde, maar niet een voldoende voorwaarde om een causaal verband vast te stellen. Anders gezegd, ook als het gevolg (bv. herstel) inderdaad optreedt na de oorzaak (bv. behandeling), dan houdt dat niet in dat de behandeling ook inderdaad het herstel heeft veroorzaakt. Misschien is het herstel wel spontaan opgetreden, of is het herstel het gevolg van een andere oorzaak waar het onderzoek niet op gericht was.
Voorbeeld 6.1: Stel je Gus voor: als iemand last heeft van brandnetel-uitslag, of een insectenbeet, of eczeem, of een blauwe plek, dan spuit Gus er wat Glassex op — en na een paar dagen is de aandoening verdwenen. Gus is ervan overtuigd dat zijn Glassex-behandeling de oorzaak is van de genezing. Maar dit is een misvatting die bekend staat als “post hoc ergo propter hoc” (na iets dus als gevolg van iets). De aandoening zou hoogstwaarschijnlijk ook goed zijn genezen zonder de Glassex-behandeling. De genezing bewijst dus niet dat de Glassex-behandeling noodzakelijk is. (Dit voorbeeld is ontleend aan de speelfilm My Big Fat Greek Wedding, 2004).
groepen van eenheden (bv. proefpersonen), doorgaans correspondeert een groep met een regel in het ontwerp.
behandeling, meestal afgebeeld als
X. Een behandeling kan ook bestaan uit het ontbreken van een behandeling (“control”), of uit het aanbieden van de niet-experimentele, gebruikelijke behandeling (“usual care”).observatie, meestal afgebeeld als
O.de toewijzing van proefpersonen aan groepen of behandelcondities kan op verschillende manieren gebeuren. Meestal doen we dat aselect (willekeurig, at random, hieronder aangegeven met
R), omdat daarmee de validiteit meestal het beste beschermd wordt.
6.2 Tussen of binnen ?
Voor het onderzoeksontwerp is het van groot belang of een onafhankelijke variabele gevarieerd wordt tussen proefpersonen of binnen proefpersonen. Voor veel taalkundig onderzoek, waarbij meerdere teksten of zinnen of woorden worden aangeboden als stimuli, geldt hetzelfde voor het onderscheid tussen stimuli of binnen stimuli.
Individuele variabelen van de proefpersonen, zoals diens geslacht (man, vrouw) of meertaligheid, kunnen normaliter alleen variëren tussen proefpersonen: eenzelfde proefpersoon kan niet meedoen aan beide geslachts-groepen van een onderzoek, en ééntalige proefpersonen kunnen niet meedoen in de groep van meertalige proefpersonen. Maar bij andere variabelen, die betrekking hebben op de wijze waarop stimuli worden verwerkt, is dat wel mogelijk. Dezelfde proefpersoon kan schrijven met zijn linkerhand en met zijn rechterhand, of kan geobserveerd worden voorafgaand aan en volgend op een behandeling. De onderzoeker moet dan in het onderzoeksontwerp kiezen op welke wijze de behandelingen en observaties worden gecombineerd. We komen daarop terug in §6.9.
6.3 Het one-shot single-case-ontwerp
Dit is een zwak ontwerp, waarbij er slechts éénmaal observaties worden gedaan, na een behandeling. Dit onderzoeksontwerp heeft het volgende schema:
X OWe zouden bijvoorbeeld kunnen tellen, voor alle eindwerkstukken van
studenten van een bepaalde opleiding van een bepaald cohort, hoeveel
fouten (van een bepaald type) er in die eindwerkstukken voorkomen. Dat
is wel een beetje interessant, maar wetenschappelijk zijn deze gegevens
echter van weinig waarde. Er kan geen enkele vergelijking gemaakt worden
met andere gegevens (van andere studenten, en/of andere werkstukken van
dezelfde studenten). Het is niet mogelijk om een valide conclusie te
trekken over mogelijke effecten van de “behandeling” (studie, X) op de
observaties (aantal fouten, O).
Soms worden de gegevens uit een one-shot-single-case-onderzoek geforceerd vergeleken met andere gegevens, bijvoorbeeld met norm-resultaten voor een grote controlegroep. Stel je voor dat we willen onderzoeken of een nieuwe methode van taalonderwijs leidt tot betere taalvaardigheid in de doeltaal. Na een cursus met de nieuwe lesmethode meten we de taalvaardigheid, en vergelijken die met de eerder gepubliceerde resultaten van een controlegroep die de traditionele lesmethode heeft gebruikt. Deze aanpak wordt veelvuldig toegepast, maar er zijn desalniettemin diverse factoren die de validiteit bedreigen (zie §5.4): o.a. geschiedenis (de nieuwe proefpersonen hebben een andere geschiedenis en levensloop gehad dan de controlegroep uit het verleden), rijping (de nieuwe proefpersonen zijn misschien verder of minder ver ontwikkeld dan de controlegroep), instrumentatie (de toets is mogelijk niet even geschikt voor personen onderwezen met de nieuwe lesmethode als met de traditionele methode), en uitval (de uitval van proefpersonen voorafgaand aan de observatie is niet bekend, noch voor de traditionele methode noch voor de nieuwe methode).
Voorbeeld 6.2: Een interviewer kan zgn. ‘gesloten’ vragen stellen met slechts enkele mogelijke antwoorden (welk van de drie groentesoorten vind je het lekkerst, doperwtjes of sperziebonen of broccoli?), of ‘open’ vragen waarin de mogelijke antwoorden niet worden beperkt door de vraagstelling (welke groente vind je het lekkerst?). Er is ook een derde categorie, nl. open vragen met voorbeeld-antwoorden (welke groente vind je het lekkerst, bijvoorbeeld doperwtjes of sperziebonen of…?). Het is echter niet duidelijk of deze voorbeeld-antwoorden wel of niet een sturend effect hebben, d.w.z. of ze meer vergelijkbaar zijn met gesloten of met open vragen. (Houtkoop-Steenstra 1991) bestudeerde opgenomen gesprekken tussen artsen en hun patiënten. De artsen stelden regelmatig open vragen met voorbeeldantwoorden. Meestal bleken de patiënten zo’n vraag niet als sturend op te vatten; zij vatten de vraag vooral op als een verzoek om te vertellen.
Dit onderzoek is te beschouwen als een one-shot-single-case-ontwerp, zonder vergelijking met gegevens uit andere condities. De conclusies zijn weliswaar gebaseerd op empirische observaties, maar we weten niet wat de geïnterviewde geantwoord zou hebben als de vraag anders gesteld zou zijn.
Ondanks al deze bezwaren kan een one-shot-case onderzoek wel van nut zijn in de observatiefase van de empirische cyclus, wanneer het gaat om het opdoen van ideeën en het formuleren van (globale) hypothesen, die later goed getoetst kunnen worden.
6.4 Het één-groep-voormeting-nameting-ontwerp
Bij het één-groep-voormeting-nameting-ontwerp worden gegevens verzameld
van één groep. Op het eerste tijdstip (meestal aangeduid als T1, maar
soms als T0) wordt een eerste meting uitgevoerd (voormeting, O1),
vervolgens wordt de groep aan de experimentele behandeling blootgesteld,
en tenslotte wordt op een later tijdstip (T2) een tweede meting
uitgevoerd (nameting, O2). In schema ziet een
één-groep-voormeting-nameting-ontwerp er als volgt uit:
O1 X O2De behandeling X varieert dus niet: iedereen krijgt dezelfde
behandeling, want er is slechts één groep. Het tijdstip van de meting,
meestal aangeduid als voormeting T0 (O1) en nameting T1 (O),
varieert binnen proefpersonen.
Dit ontwerp is over het algemeen beter beter dan het vorige
one-shot-case-ontwerp én beter dan helemaal geen gegevens. Toch
beschouwen wij het als een zwak onderzoeksontwerp, omdat diverse
bedreigingen van de validiteit niet goed ondervangen worden (zie
§5.4). Een eventueel verschil tussen O2
en O1 kan niet uitsluitend toegeschreven worden aan de tussenliggende
behandeling X: dit effect kan ook het gevolg zijn van rijping (de
verbetering is het gevolg van rijping van de proefpersonen) of van
geschiedenis (de verbetering is het gevolg van een of meerdere
gebeurtenissen anders dan X die zijn opgetreden tussen de tijdstippen
van O1 en O2). Als de behandeling X of de nameting O2
afhankelijk is van de score op de voormeting O1, dan kan ook de
regressie naar het gemiddelde de validiteit bedreigen. Kortom, aan dit
onderzoeksontwerp kleven diverse bezwaren, omdat de hypothese over het
effect van de onafhankelijke variabele niet zonder meer op valide wijze
beantwoord kan worden.
6.5 Het voormeting-nameting-controlegroep-ontwerp
De bovengenoemde problemen kunnen voor een deel ondervangen worden door
een controlegroep toe te voegen aan het ontwerp; we krijgen dan een
voormeting-nameting-controlegroep-ontwerp. Er zijn dan dus twee groepen
van elementen (proefpersonen). In schema wordt dat weergegeven door twee
regels. Dit onderwerp wordt zeer vaak gebruikt. Waar mogelijk proberen
onderzoekers de twee groepen zo vergelijkbaar mogelijk te maken, door de
proefpersonen aselect (at random, willekeurig, volgens toeval) toe te
wijzen aan de twee groepen. In schema ziet dit model er als volgt uit
(de R staat voor random toewijzing aan de twee groepen):
R O1 X O2
R O3 O4Dit onderzoeksontwerp is populair, omdat het veel mogelijke bedreigingen
van de interne validiteit kan ondervangen (zie
§5.4). Het effect van de manipulatie of
behandeling (X) wordt geëvalueerd door een vergelijking van de twee
verschillen (O2-O1) en (O4-O3). Dit onderzoeksontwerp heeft
eigenlijk niet één maar twee onafhankelijke variabelen, die van invloed
kunnen zijn op de metingen: (1) de manipulatie of behandeling, X of
niet-X, variërend tussen proefpersonen, en (2) het tijdstip van de
meting, meestal aangeduid als voormeting T0 en nameting T1,
variërend binnen proefpersonen.
In dit ontwerp wordt wel rekening gehouden met de effecten van geschiedenis, althans voor zover die effecten voor beide groepen in gelijke mate zijn opgetreden. Er wordt geen rekening gehouden met gebeurtenissen die slechts één van de groepen (condities) hebben beïnvloed. Als er wel zo’n gebeurtenis is geweest voor de ene groep en niet voor de andere groep, dan kan dat verschil in geschiedenis dus ook verantwoordelijk zijn voor een ongelijk verschil tussen voormeting en nameting in de ene groep ten opzichte van de andere groep.
De bedreiging van de interne validiteit door rijping kan in dit
onderzoeksontwerp makkelijk opgevangen worden. Een effect van rijping
komt immers naar verwachting in beide groepen in gelijke mate tot
uiting, en kan daarom niet van invloed zijn op het verschil tussen
(O2-O1) en (O4-O3). Natuurlijk gaan we er hierbij vanuit dat de
voormetingen voor de twee groepen resp. de nametingen voor de twee
groepen op hetzelfde tijdstip zijn afgenomen.
Ook een storend effect van instrumentatie wordt geneutraliseerd, als aan de eisen voor vergelijkbare afnamecondities voldaan wordt, en als gemeten wordt met hetzelfde instrument, zoals hetzelfde apparaat of computerprogramma of gedrukte toets. Wanneer echter observatoren of beoordelaars ingeschakeld moeten worden, zoals bij onderzoek naar de schrijfvaardigheid, dan wordt de instrumentatie een moeilijker factor. Het is dan van groot belang dat deze beoordelaars niet weten door welke proefpersonen of onder welke conditie de te beoordelen producten of responsies tot stand zijn gekomen. Anders zouden hun verwachtingen (onbewust en onbedoeld) een rol kunnen spelen bij het tot stand komen van hun oordeel. In dat geval zou niet een effect van de onafhankelijke variabele aangetoond worden, maar een effect van de vooringenomenheid van beoordelaars.
Ook het probleem van regressie naar het gemiddelde speelt in dit ontwerp
een kleinere rol. Indien de proefpersonen aselect zijn toegewezen aan de
twee groepen, én de gegevens van alle proefpersonen gelijktijdig in een
analyse betrokken worden, dan speelt regressie naar het gemiddelde geen
enkele rol. In beide groepen treedt immers regressie naar het gemiddelde
op, en naar verwachting in gelijke mate, waardoor dat niet van invloed
is op de analyse van het verschil tussen (O2-O1) en (O4-O3).
Selectie van proefpersonen wordt in dit onderzoeksontwerp uitgesloten door de steekproef van proefpersonen aselect te kiezen uit de populatie, en door daarna de proefpersonen wederom aselect toe te wijzen aan de twee groepen of condities. Natuurlijk geldt hier de wet van de grote getallen: als een grotere steekproef aselect wordt gesplitst in twee groepen, dan is ook de kans groter dat de twee groepen gelijkwaardig zijn, ten opzichte van een kleinere steekproef.
Uitval kan wel degelijk een oorzaak zijn voor een verschil tussen
(O2-O1) en (O4-O3). Deze voor de validiteit bedreigende factor
is moeilijk te beheersen. We kunnen proefpersonen immers niet dwingen om
aan een onderzoek te blijven meewerken, of om niet te verhuizen, of niet
te overlijden. Uitval kan dus een probleem zijn, zeker wanneer er een
verschil in uitval is tussen de twee groepen of condities. Het is goed
gebruik om de uitval te melden in het onderzoeksverslag, en de mogelijke
gevolgen ervan te bespreken.
Met dit voormeting-nameting-controlegroep-ontwerp kunnen de verschillende factoren die de interne validiteit bedreigen dus redelijk goed beheerst worden. Maar hoe zit het met de constructvaliditeit (zie §5.5)? Deze bedreigingen hebben we niet eerder aangeroerd bij het one-shot-case-ontwerp en het één-groep-voormeting-nameting-ontwerp, omdat bij deze onderzoeksontwerpen de interne validiteit al twijfelachtig was.
Niet alle aspecten van de constructvaliditeit hebben echter repercussies op het onderzoeksontwerp. Sommige aspecten met betrekking tot de wijze van operationalisatie, zoals convergente en divergente validiteit, zijn niet relevant voor de keuze van het onderzoeksontwerp. Maar andere aspecten zijn wel relevant: de verwachtingen van de onderzoeker, aandacht, motivatie, en de sturende werking van de voormeting.
Het voormeting-nameting-controlegroep-onderzoeksontwerp biedt voor geen
van deze vier bedreigingen van de constructvaliditeit adequate
waarborgen. De verwachtingen van de onderzoeker kunnen in zowel de
experimentele als de controle-conditie een (verschillende) rol spelen,
omdat in beide condities op twee tijdstippen gemeten wordt. Bovendien
kan een eventueel verschil tussen (O2-O1) en (O4-O3) ook te
wijten zijn aan de (extra) aandacht die aan de experimentele conditie
besteed is: het zgn. Hawthorne-effect (zie Voorbeeld 5.10 in Hoofdstuk 5).
Dit effect speelt vooral een rol als de
proefpersonen in de ene conditie (groep) meer aandacht krijgen dan in de
andere, zoals in het onderstaande voorbeeld.
Een derde bedreiging van de constructvaliditeit van een onderzoek is de motivatie. Soms kan één van de condities zo demotiverend werken dat de proefpersonen in deze conditie niet meer serieus aan het onderzoek meewerken. Net als bij aandacht gaat het niet zozeer om de aantrekkelijkheid van één van de condities, maar om de verschillen in aantrekkelijkheid tussen de onderzoekscondities.
In het voormeting-nameting-controlegroep-ontwerp kan de
constructvaliditeit tevens bedreigd worden door de sturende werking van
de voormeting. Door een voormeting (O1 en O3) kunnen de
proefpersonen zich van bepaalde aspecten van het onderzoek (meer) bewust
worden, waardoor zij zich daarna niet meer als naïeve proefpersonen
gedragen. De voormeting kan dan als een soort manipulatie beschouwd
worden (zie Voorbeeld 6.3 hieronder).
6.6 Het Solomon-vier-groepen-ontwerp
Het Solomon-vier-groepen-ontwerp wordt veel minder vaak gebruikt dan het voormeting-nameting-controlegroep-ontwerp. Toch verdient dit ontwerp duidelijk de voorkeur boven het voormeting-nameting-controlegroep-ontwerp. Met name bedreigingen van de constructvaliditeit worden in dit ontwerp beter onder controle gehouden.
In het Solomon-vier-groepen-ontwerp worden vier condities onderscheiden. De proefpersonen worden aselect toegewezen aan een van deze vier condities. In de eerste twee condities wordt eerst een voormeting gehouden, waarna één van de groepen aan de experimentele behandeling blootgesteld wordt. Daarna volgt voor beide groepen een nameting. Tot zover is het Solomon-vier-groepen-ontwerp dus exact gelijk aan het voormeting-nameting-controlegroep-ontwerp. In de derde en vierde conditie wordt echter géén voormeting gehouden. In de ene conditie worden de proefpersonen wel aan de experimentele behandeling blootgesteld, maar in de andere conditie niet. Tot slot maken deze beide groepen weer een nameting. Schematisch kan het Solomon-vier-groepen-ontwerp als volgt weergegeven worden:
R O1 X O2
R O3 O4
R X O5
R O6Het Solomon-vier-groepen-ontwerp is dus een uitbreiding van het
voormeting-nameting-controlegroep-ontwerp met twee groepen, die niet
meedoen met de voormeting. Door de twee extra condities zonder
voormeting kan rekening gehouden worden met de sturende werking van de
voormeting: die sturende werking is immers niet aanwezig in de
derde en vierde groep. Bovendien wordt het effect van de manipulatie van
de onafhankelijke variabele X verschillende malen getoetst, in de vier
vergelijkingen van O2 en O1, O2 en O4, O5 en O6, en
(O2-O1) en (O4-O3). Het effect van de mogelijk sturende
voormeting wordt getoetst in de twee vergelijkingen van O2 en O5,
en O4 en O6. We kunnen dus in één onderzoek zowel een effect van
de behandeling als van de voormeting aantonen. Daarvoor moeten we echter
wel twee extra groepen proefpersonen inzetten (ten opzichte van het
voormeting-nameting-controlegroep-ontwerp).
Voorbeeld 6.3: In een onderzoek (Ayres, Hopf, and Will 2000) werd het effect onderzocht van een gewenningstraining (
X) op de angst om in het openbaar te spreken. Spreekangst werd gemeten door de proefpersoon eerst een toespraak te laten houden, en daarna twee vragenlijsten over spreekangst te laten invullen. Bij elkaar vormt dat één meting. De gewenningstraining voor de ene groep bestond uit het bekijken van een trainingsvideo van ca 20 minuten; de tweede groep kreeg in plaats daarvan een pauze van dezelfde duur. Het onderzoek gebruikte een Solomon-vier-groepen-ontwerp om een mogelijk sturende werking van de voormeting te kunnen onderzoeken. Het is immers mogelijk dat de voormeting (waarvan een spreekbeurt deel uitmaakt) zelf al een training vormt voor de proefpersonen, zodat de gunstige effecten na de “behandeling”X(gewenningstraining) niet toegeschreven kunnen worden aan die behandeling, maar (mede) aan die voormeting. De resultaten lieten echter zien dat de gewenningstraining inderdaad een sterk (gunstig) effect had op de spreekangst, en dat de voormeting alleen (dus zonder behandeling) geen enkel effect had op de mate van spreekangst bij de proefpersonen.
6.7 Het nameting-controlegroep-ontwerp
In heel veel onderzoekingen wordt een voormeting uitgevoerd, omdat de onderzoekers willen onderbouwen dat de twee (of meer) onderzoeksgroepen niet van elkaar verschillen bij de aanvang van het onderzoek. Toch is die voormeting niet een essentieel onderdeel van een adequaat onderzoeksontwerp. Als de groepen voldoende groot zijn, en als de proefpersonen (of andere onderzoekseenheden) geheel volgens het toeval zijn toegewezen aan de groepen, dan zijn de twee groepen op statistische gronden al goed vergelijkbaar. Als we bijvoorbeeld 100 proefpersonen geheel volgens het toeval verdelen over 2 groepen, dan is de kans buitengewoon klein dat de twee groepen zouden verschillen in de voormeting. In veel van dit soort gevallen kan dan ook volstaan worden met een nameting-controlegroep-ontwerp, schematisch weergegeven als volgt:
R X O5
R O6Dit ontwerp is echter alleen adequaat indien de groepen voldoende groot zijn, en indien de proefpersonen aselect zijn toegewezen aan de condities. Als dat niet mogelijk is, dan voldoet dit ontwerp ook niet.
Voorbeeld 6.4: In vervolg op het onderzoek van (Houtkoop-Steenstra 1991) (Voorbeeld 6.2) onderzochten (Wijffels, Bergh, and Dillen 1992) in hoeverre vragen met danwel zonder voorbeeldantwoorden in een mondeling (telefonisch) vraaggesprek als sturend werden opgevat. Hiertoe werden vijf vragen geconstrueerd over criminaliteit. Van elke vraag werden twee versies geconstrueerd: één met en één zonder voorbeeldantwoorden. Aan elke respondent (van een steekproef van 50) werden twee of drie vragen gesteld met voorbeeldantwoorden, en twee of drie vragen zonder voorbeeldantwoorden. De toedeling van vragen met en zonder voorbeeldantwoorden was gerandomiseerd, en daardoor mogen we aannemen dat de groep respondenten die een bepaalde vraag met voorbeeldantwoorden kreeg niet verschilt van de groep respondenten die dezelfde vraag zonder voorbeeldantwoorden kreeg. Als beide groepen dezelfde (soort) antwoorden geven, dan hebben de voorbeeldantwoorden blijkbaar geen sturend effect, maar indien de respondenten vaak antwoorden met de gegeven voorbeeldantwoorden dan hebben de voorbeelden blijkbaar wel een sturend effect. Bij analyse bleek dat voor vier van de vijf vragen een dergelijk sturend effect inderdaad optrad.
De twee onderzoeken van (Houtkoop-Steenstra 1991) en (Wijffels, Bergh, and Dillen 1992) illustreren hoe wetenschappelijke kennis zich ontwikkelt. (Houtkoop-Steenstra 1991) constateert dat de vakliteratuur zich voornamelijk bezig heeft gehouden met schriftelijke interviews, en vraagt zich af of de effecten bij mondelinge ‘face-to-face’-interviews hetzelfde zijn. Zij concludeert dat voorbeeldantwoorden niet sturend werken in deze ‘face-to-face’-gesprekken. (Wijffels, Bergh, and Dillen 1992) onderzoeken dezelfde hypothese in een experiment, met mondelinge interviews per telefoon, en zij concluderen dat voorbeeldantwoorden wel degelijk sturend werken in deze telefonische gesprekken.
6.8 Factoriële ontwerpen
Tot nog toe hebben we het gehad over experimentele onderzoeksontwerpen waarbij één onafhankelijke variabele gemanipuleerd wordt. Veel onderzoekers zijn echter (ook) geïnteresseerd in de effecten van de gelijktijdige manipulatie van meerdere onafhankelijke variabelen. Ontwerpen waarin meerdere factoren gelijktijdig variëren noemen we factoriële ontwerpen. We kwamen deze al tegen bij het voormeting-nameting-controlegroep-ontwerp (§6.5 waar zowel de tijd als de behandeling varieert.
Voorbeeld 6.5: Drake and Ben El Heni (2003) onderzochten de waarneming van muzikale structuur. Die waarneming kan indirect gemeten worden door de luisteraar te vragen om mee te tikken met de muziek. Als een luisteraar de muzikale structuur niet begrijpt of herkent, is hij geneigd mee te tikken met iedere tel (analytisch luisteren). Naarmate een luisteraar de muzikale structuur beter begrijpt en herkent, is hij meer geneigd om mee te tikken met hogere nivo’s (synthetisch of voorspellend luisteren): hij tikt dan niet bij iedere tel, maar bv \(1\times\) per maat of per muzikale frase. De tijdsafstand (‘inter-onset-interval’, IOI) tussen de tikken vormt aldus een indicatie van de waargenomen muzikale structuur. Aan het onderzoek van deden twee groepen luisteraars mee, in Frankrijk en in Tunesië9. Alle proefpersonen luisterden naar 12 muziekstukken, waarvan 6 afkomstig uit de Franse en 6 uit de Tunesische muzikale culturen (de muziekstukken waren verschillend qua maatsoorten, tempi, en mate van bekendheid). De resultaten zijn grafisch samengevat in Figuur 6.1.
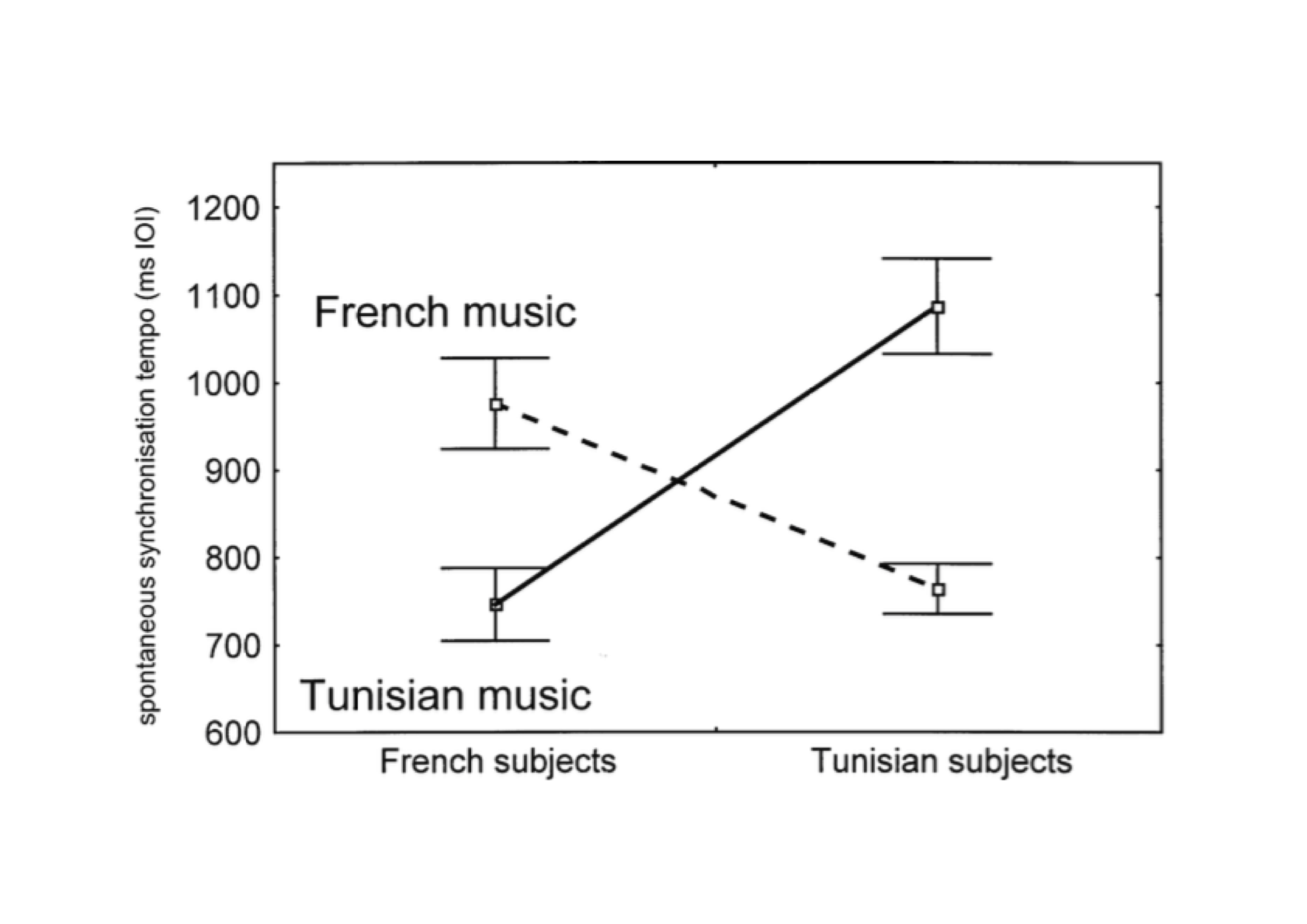
Figuur 6.1: Gemiddelde tijdsafstand tussen tikken (IOI, in ms) voor twee groepen luisteraars en twee muzieksoorten (ontleend aan Drake and Ben El Heni, 2003, Fig.2).
Uit deze resultaten blijkt dat er géén verschil optreedt tussen de groepen (Franse vs Tunesische luisteraars; de twee groepen hebben gemiddeld dezelfde IOI), en dat er ook géén verschil optreedt tussen de muzieksoorten (Franse vs Tunesische muziekstukken; de twee muzieksoorten resulteren in gemiddeld dezelfde IOI). Hebben de twee onafhankelijke variabelen dan geen enkel effect? Toch wel! De Franse luisteraars bleken langere IOI’s tussen tikken te produceren als ze naar Franse muziek luisterden, terwijl de Tunesische luisteraars daarentegen langere IOI’s produceerden als ze naar Tunesische muziek luisterden. Alle luisteraars blijken dus langere IOI’s te produceren als ze luisteren naar een muzieksoort die voor hen bekend is, en kortere IOI’s als ze luisteren naar een onbekende muzieksoort. Drake and Ben El Heni (2003) concluderen dat de luisteraars beter in staat zijn om muzikale structuur te herkennen en te begrijpen in muziek van hun eigen muzikale cultuur dan in die van een andere cultuur. Dit patroon van resultaten is een klassiek kruislings interactie-effect, waarbij het effect van de ene onafhankelijke variabele precies tegengesteld is in de verschillende condities van de andere onafhankelijke variabele.
Als er een interactie-effect blijkt op te treden, dan is het zinloos om een eventueel hoofdeffect te interpreteren. Dat werd al geïllustreerd in Voorbeeld 6.5 hierboven: we kunnen niet concluderen dat er géén verschil is tussen de muzieksoorten. Maar de grootte (en richting) van het verschil is afhankelijk van de andere onafhankelijke variabele(n), nl. van de groep/nationaliteit van de luisteraars. Veel onderzoek is er juist op gericht om interactie-effecten aan te tonen; niet de hoofdeffecten maar hun interactie vormt het onderwerp van onderzoek, net als in het bovenstaande voorbeeld 6.5.
Een factorieel onderzoeksontwerp is lastig om schematisch weer te geven,
omdat er meerdere onafhankelijke variabelen (met elk weer meerdere
niveaus) in voorkomen. We zouden deze schematisch kunnen representeren
door de manipulatie, die we voorheen aangeduid hebben met een X, te
indiceren. De eerste index (subscript) geeft dan het niveau aan voor de
eerste onafhankelijke variabele of factor, en de tweede index geeft het
niveau aan van de tweede factor. Het ontwerp van voorbeeld 6.5 wordt dan als volgt schematisch weergegeven:
R X_{1,1} O1
R X_{1,2} O2
R X_{2,1} O3
R X_{2,2} O4Het is vaak verleidelijk om meerdere factoren te combineren in één groot factorieel onderzoeksontwerp, zodat we kunnen onderzoeken hoe al die factoren op elkaar inwerken (interageren). Toch is het verstandig om dat niet te doen, en om het aantal factoren beperkt te houden. Ten eerste, zoals we later zullen zien, moet het aantal observaties ongeveer gelijke tred houden met het aantal verschillende combinaties van factoren. Als je meer combinaties van factoren toevoegt, dan zijn er daardoor ook veel meer proefpersonen nodig (of andere eenheden). Ten tweede is het moeilijker te garanderen dat alle combinaties van factoren perfect vergelijkbaar zijn (Shadish, Cook, and Campbell 2002, 266): zijn Tunesische deelnemers die in Tunesië luisteren naar Tunesische muziek wel goed vergelijkbaar met Franse deelnemers die in Frankrijk luisteren naar Franse muziek? De vergelijkbaarheid van combinaties wordt lastiger, naarmate er meer combinaties van factoren in het onderzoek voorkomen. Ten derde zijn interacties notoir moeilijk te interpreteren, en dat wordt eveneens lastiger naarmate de interacties complexer zijn, en meer factoren omvatten. Om al deze redenen is het beter om effecten van meerdere factoren te bestuderen in verschillende afzonderlijke onderzoeken (Quené 2010).
We zullen later terugkomen op de analyse en interpretatie van gegevens uit factoriële onderzoeksontwerpen (Hoofdstuk 15). Voorlopig concentreren we ons op ontwerpen met slechts één onafhankelijke variabele.
6.9 Afhankelijke- en onafhankelijke-groepen-ontwerp
In het begin van dit hoofdstuk hebben we gesproken over de manipulatie van een onafhankelijke variabele tussen danwel binnen proefpersonen (6.2). In de meeste van de voorafgaande onderzoeksontwerpen werd voor elke waarde van de onafhankelijke variabele(n) een afzonderlijke groep geformeerd; we noemen dat een onafhankelijke-groepen-ontwerp. De onafhankelijke variabele varieert tussen proefpersonen.
Sommige onafhankelijke variabelen kunnen echter ook gevarieerd worden binnen proefpersonen. We meten dan herhaaldelijk bij (binnen) dezelfde proefpersonen uit dezelfde groep, onder verschillende condities van de onafhankelijke variabele. In het onderstaande voorbeeld wordt de onafhankelijke variabele ‘taal’ (moedertaal of vreemde taal) gevarieerd binnen proefpersonen. We noemen dat een afhankelijke-groepen-ontwerp.
Voorbeeld 6.6: (De Jong et al. 2015) onderzochten de vloeiendheid van de spraak van proefpersonen in hun moedertaal (Turks) en in een vreemde taal (Nederlands). De proefpersonen voerden eerst een aantal spreektaken uit in hun moedertaal, en enkele weken later in het Nederlands. Eén van de afhankelijke variabelen was het aantal gevulde pauzes (bijv. eh, ehm) per seconde spraak: hoe meer pauzes, hoe minder vloeiend. De sprekers bleken meer pauzes te produceren (d.w.z. minder vloeiend te spreken) in de vreemde taal dan in hun moedertaal, zoals ook te verwachten is. Eén van de doelen van het onderzoek was overigens om te onderzoeken in hoeverre individuele verschillen in vloeiendheid in de vreemde taal te herleiden zijn naar individuele verschillen in vloeiendheid in de moedertaal. De samenhang tussen de twee metingen bleek hoog (correlatie \(r=0.73\), meer hierover in Hoofdstuk 11. Sprekers die veel pauzeren in de vreemde taal, doen dat vaak ook in hun moedertaal. De onderzoekers bepleiten dat met deze correlatie rekening gehouden moet worden bij het aanleren en toetsen van spreekvaardigheid in een vreemde taal.
Het hier beschreven onderzoeksontwerp ziet er in schema als volgt uit:
X1 O1 X2 O2Ondanks de vele mogelijke bedreigingen van de interne validiteit (o.a. geschiedenis, rijping, sturende werking van de voormeting) is zo’n ontwerp in veel gevallen nuttig. In het bovenstaande voorbeeld is het essentieel dat dezelfde proefpersonen spreektaken uitvoeren in beide talen (condities) — de onderzoeksvragen zijn niet met een andere methode te beantwoorden.
6.10 Onderzoek ontwerpen
Een onderzoeker die een onderzoek wil uitvoeren, moet bepalen op welke wijze hij zijn gegevens gaat verzamelen: hij moet een keuze maken voor een bepaald onderzoeksontwerp. Soms kan een standaard-ontwerp gekozen worden, zoals een van de hierboven behandelde ontwerpen. In andere gevallen zal de onderzoeker zelf het ontwerp moeten opstellen. Het ontwerp moet uiteraard goed aansluiten bij de onderzoeksvraag (Levin 1999), en het moet zoveel mogelijk storende variabelen uitsluiten die de validiteit zouden kunnen bedreigen. Het ontwerpen van onderzoek is een vak dat onderzoekers al doende leren. In het onderstaande voorbeeld proberen we weer te geven welke redenering en argumenten een rol spelen bij de ontwikkeling van een onderzoeksontwerp.
Stel je voor dat we willen onderzoeken of de vorm waarin toetsvragen gesteld worden, als open vs. gesloten vragen, van invloed is op de scores op die toets. In een eenvoudig ontwerp nemen we eerst een toets af met open vragen, en daarna een vergelijkbare toets met gesloten vragen, bij dezelfde respondenten. Als de samenhang tussen de scores hoog genoeg is, dan wordt geconcludeerd dat beide toetsen hetzelfde meten, en dat de prestatie niet wezenlijk beïnvloed wordt door de vorm waarin de vragen worden gesteld. Schematisch is dit ontwerp als volgt weer te geven:
Open O1 Gesloten O2Dit onderzoeksontwerp heeft echter diverse zwakke punten. Ten eerste is het onverstandig om eerst alle toetsen met open vragen op het eerste tijdstip af te nemen, en vervolgens alle toetsen met gesloten vragen op het tweede tijdstip. De prestaties op de tweede toets worden immers altijd beïnvloed door volgorde-effecten (transfer): de respondenten hebben iets onthouden en dus geleerd van de eerste meting. Deze transfer werkt nu altijd dezelfde kant op, met daardoor (vermoedelijk) relatief hogere prestaties bij de toets met gesloten vragen (op het tweede tijdstip). Het is dus beter om de toetsen met open en gesloten vragen gelijkelijk te verdelen over het eerste en tweede tijdstip van afname.
Ten tweede kunnen alle respondenten beïnvloed zijn door eventuele gebeurtenissen tussen de twee tijdstippen (geschiedenis), bijvoorbeeld door een relevante instructie over het onderwerp van de toets. Omdat er geen controle-groep is, kan met zo’n effect geen rekening worden gehouden.
Een derde probleem is gelegen in de wijze waarop van bevindingen naar conclusie wordt geredeneerd. Zoals gezegd, houdt die redenering in dat, als de samenhang tussen de scores hoog genoeg is, dan beide toetsen hetzelfde meten. Als je daarover nadenkt, dan ben je het misschien met ons eens dat dat een vreemde redenering is. De onderzoeksvraag is eigenlijk, of de samenhang in prestaties op verschillende toetsen met verschillende vraagvormen even hoog is als de samenhang in prestaties op verschillende toetsen met dezelfde vraagvormen, waarvan we immers aannemen dat die hetzelfde meten. Daarmee hebben we in feite een controle-groep gedefinieerd, nl. respondenten die op beide tijdstippen toetsen maken met dezelfde vraagvorm. Voor alle zekerheid voegen we niet één maar twee controle-groepen toe, met open resp. gesloten toetsvragen op beide tijdstippen.
We hebben het ontwerp zo in tenminste twee opzichten verbeterd: (1) de open en gesloten toetsen zijn gelijkelijk verdeeld over de twee opname-tijdstippen, en (2) er zijn relevante controle-groepen toegevoegd. Schematisch ziet het onderzoeksontwerp er nu als volgt uit:
R Exp. groep 1 Open O1 Gesloten O2
R Exp. groep 2 Gesloten O3 Open O4
R Controlegroep 1 Open O5 Open O6
R Controlegroep 2 Gesloten O7 Gesloten O8Voor alle vier de groepen kan nu de samenhang tussen de prestaties op het eerste en tweede tijdstip bepaald worden. Vervolgens kunnen we deze samenhang-resultaten uit de vier groepen vergelijken, en daarmee de onderzoeksvraag beantwoorden. Dit voorbeeld laat goed zien dat de conclusies die je uit de onderzoeksresultaten kunt trekken, direct afhankelijk zijn van het gekozen ontwerp (Levin 1999). In het eerste ontwerp leidt een lage gevonden samenhang tot de conclusie dat de twee onderzochte toetsvormen niet een beroep doen op dezelfde intellectuele vaardigheden bij de respondenten. In het tweede ontwerp hoeft dezelfde lage samenhang in de derde groep (experimentele groep 1) echter niet tot dezelfde uitkomst te leiden! De conclusie hangt immers mede af van de mate van samenhang gevonden in de andere groepen.
6.11 Tenslotte
Ondanks alle beschikbare boeken, handleidingen, websites, en ander instructiemateriaal komen wij nog te vaak onderzoek tegen waar methodologisch iets mis is in de onderzoeksvragen, operationalisatie, onderzoeksopzet, steekproeftrekking, en/of dataverwerking. Die problemen veroorzaken niet alleen een verspilling van tijd, geld en energie, maar ze resulteren ook in kennis die minder betrouwbaar, valide en robuust is dan mogelijk. De onderstaande ‘checklist’ voor goed onderzoek (deels ontleend aan https://www.linkedin.com/groups/4292855/4292855-6093149378770464768) kan veel ellende in latere stadia van een onderzoek voorkomen.
Denk goed na over je onderzoeksvragen, en formuleer ze helemaal uit. Als de vragen niet helder geformuleerd zijn, of als er veel deelvragen zijn, denk dan verder na.
Prioriteer de onderzoeksvragen. Dit helpt bij het maken van keuzes in onderzoeksontwerp, steekproeftrekking, operationalisatie, e.d.
Denk goed na over het ontwerp van het onderzoek. Volgens de overlevering levert ieder uur nadenken over je onderzoeksontwerp een toekomstige besparing van ongeveer 10 uren tijdens de data-analyse en interpretatie. Anders gezegd: een uur minder nadenken over je ontwerp kost je later 10 uur extra werk.
Bedenk ook alternatieve onderzoeksontwerpen, en denk na over de voordelen en nadelen van de diverse mogelijke ontwerpen.
Stel je de toekomst voor: je hebt het onderzoek uitgevoerd, de gegevens zijn geanalyseerd, en je hebt het verslag of de scriptie of het artikel geschreven. Welke boodschap wil je overbrengen op de lezers van dat verslag? Hoe draagt het onderzoeksontwerp bij aan die boodschap? Wat zou je kunnen veranderen in je ontwerp om die boodschap nog duidelijker te maken? Bedenk waar je naar toe wilt, niet alleen waar je nu staat.
Schrijf een onderzoeksplan, waarin je de verschillende methodologische aspecten beschrijft. Beargumenteer en expliciteer je onderzoeksvragen, onderzoeksontwerp, steekproef, meetmethode, data-verzameling, meetinstrumenten (bv. vragenlijst, software), andere benodigdheden (bv. laboratorium, vervoer), en statistische verwerking. Onderdelen van dit onderzoeksplan zijn later herbruikbaar in het onderzoeksverslag. Maak daarbij ook een tijdsplanning: wanneer zullen welke mijlpalen zijn bereikt?
Schrijf uit hoe je de verzamelde gegevens statistisch zult analyseren, nog voordat je begint met de eigenlijke data-verzameling. Wees daarbij weer zo expliciet mogelijk (in een script, stappenplan, o.i.d.). Maak een mini-dataverzameling van een redelijk aantal fictieve observaties of werkelijke observaties uit de pilot-fase van het onderzoek, en analyseer deze gegevens alsof het de definitieve data-verzameling betreft. Maak eventueel aanpassingen in je onderzoeksplan.
Als je eenmaal doende bent gegevens te verzamelen, maak dan geen wijzigingen meer in het onderzoeksplan. Houd je aan dat plan en aan de bijbehorende tijdsplanning. Analyseer de gegevens op de wijze zoals vastgelegd in het (aangepaste) onderzoeksplan. Bespreek eventuele problemen die tijdens het onderzoek optraden wel in het onderzoeksverslag. Als er grote problemen optreden, breek dan het onderzoek af, en overweeg een verbeterde versie van je onderzoek.
Referenties
Merk op dat proefpersonen niet aselect zijn toegewezen aan een van deze groepen, en dat dit dus strikt genomen een quasi-experimenteel onderzoek is (zie Hoofdstuk 1).↩︎